Predicting Customers


Using a Gradient Boosting Machine on survey data to characterise potential customers.
Disclaimer: this has aged (it was about actual TV after all) and I would probably update a few things here or there. I was young and needed the experience. Some things are fun though, but don't think about running this on your mobile.
The Objective
This thing explained the outcomes of a predictive model being run on a large corpus of survey questions about TV usage. Working for a broadcaster at the time we had 25,000 responses from a year long survey about TV habits and usage and were interested in key viewing and subscription drivers.
What do potential customers look like and how do they differ from non-potential customers? Who are they? How are they watching TV? What are they watching?
Note, that while the category labels have been anonymised, the outcomes are real.
The Data
As said, around 25,000 people answered a 70 questions long interview within one year for this analysis. The answers are all coded within a single table, respondents in the rows, questions in the columns. Our first task is to extract all information and put it into a dataset our model can read. All we really need to know here regarding the model-requirements is that we don't want any missing data in our model data. In case the data doesn't come the way we want (it rarely does) we have to reshape it. In our case we want a 0 or a 1 for each respondent for every possible answer.
So if there's a single question asking 'Which of the following Films have you watched last year?', a list of answers might consist of a selection of 5 films. If you have watched Film 1 and Film 3 of the selection, we want the following table for you:
| Film 1 | Film 2 | Film 3 | Film 4 | Film 5 |
|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 |
You can see how the number of variables can increase dramatically from a questionnaire with only 70 questions to a dataset of not 70 but over 3000 variables. Especially with longer lists than Film 1 to Film 5.
The Models
The model's task is best summarised by 'noise reduction' and 'characterisation'. Focussing first on the former, we should be choosing our weapons appropriatley. In this case I went for 2 models: a Logistic Regression with Lasso shrinkage as well as a Gradient Boosting Machine. The Logistic Regression calculates a weight for each variable, sticks the weights as well as the variable values in a long equation and calculates a value between 0 and 1 for each respondent. This value can then be read as a likelihood to be either a Potential (being a 1) or a Non-potential (being a 0). One could say all respondents who are 0.5 and beyond are a Potential customer all below 0.5 are a Non-potential. While calculating these weights we can add a so called shrinkage- or regularisation factor to the formula that calculates our parameter weights (the loss function). This factor has the effect that the calculation tries to minimise the weights as much as possible - with a Lasso regularization to 0. If a weight is 0 the variable gets excluded from our model and we have one variable less. In most circumstances with many variables this is the behaviour we want as we will be left with solely important and meaningful variables for predicting our outcome - being a potential customer or not.
The second model, the Gradient Boosting Maching, uses a slightly different approach. In many cases it's assumed to be superior to the Lasso Regression. The Gradient Booster builds a tree. In fact it builds a lot of trees. What is a tree? A tree (aka decision tree) is a statistical model that partitions the data into coherent segments and then calculates how good these segments are to predict the outcome. It tries a few variables and a number of values from that variable to set the split and for every iteration calculates the prediction error before settling for the best incision. Once the first partition is made it continues its search for the best split on the 2nd level, the 3rd level, the 4th level and so on. Additionally we apply a boosting techinque meaning that we sequentelly build small trees that learn from the previous tree. The learning happens in that a tree is fitted to the error and included as part of the new tree calculation. Put in slightly ethereal wording this forces the new tree to learn from the mistakes of the old tree and improves the overall prediction.
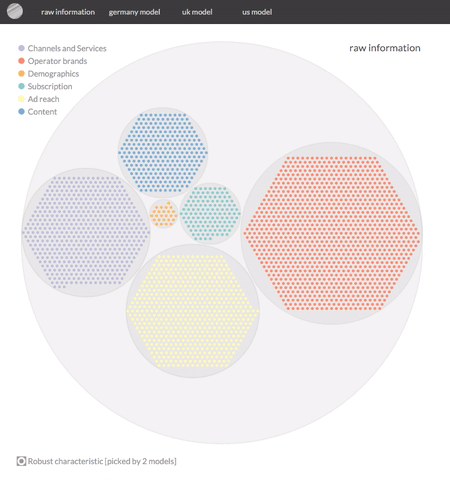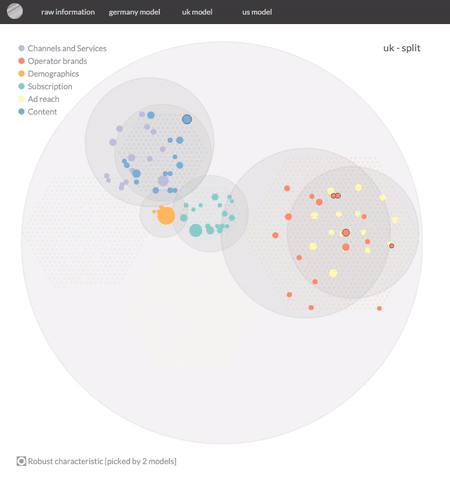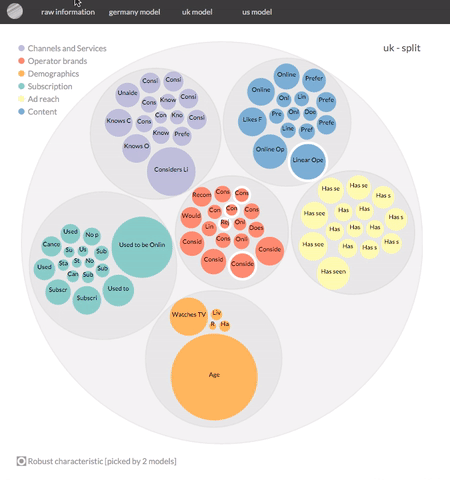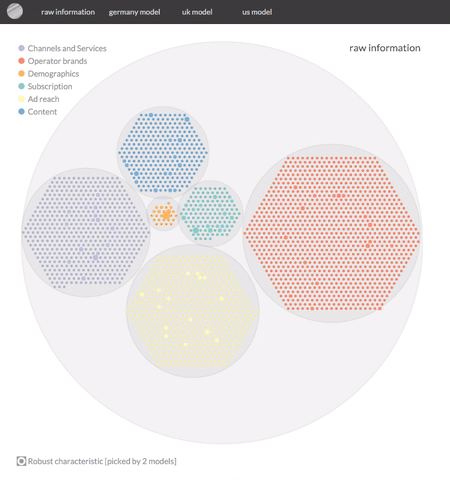
In both cases the analysis will yield a likelihood per respondent to be a potential customer or not. That's great for analyses with a prediction objective. However, in our case we are mainly interested in reducing noise and isolating variables that help us characterise potential customers. So more importantly the model will return a significantly reduced set of variables (from c. 3000 to around 100), helping us to characterise our potential customers. This second output is the gem we're after.
The Visual
While these models are powerful in the analysis, they remain black-boxes for most readers. They yield question marks at best and skepticisim at worst. The best is probably not to mention Lasso shrinkage and Gradient Boosting too often. However, we still need to describe the process in order to raise some understanding about the aim and the result of our analysis.
In order for the analysys to get accepted, the models need to be sold. A well structured and succinct power-point can go some way, but animation and interactivity in a visual explanation helped in this case to get readers to lean forward in their own time.
 it's snowing people
it's snowing people
As such, this example visualization has 2 main parts to it: it starts with an optional animated explanation and then allows user-driven interactivity.
There are clearly more complex and elaborate systems the like out in the wild, but this principle of narrative introduction to user-driven interactivity I found to be a very effective way to engage cognition to promote self-driven understanding.